Si vous vous demandez comment fonctionne l’IA, retenez une idée simple : elle ne pense pas, elle calcule une réponse à partir d’exemples, de règles d’apprentissage et d’un objectif. Dans cet article, vous allez comprendre la chaîne complète données, entraînement, modèle, inférence, puis apprendre à distinguer IA classique, machine learning, deep learning, IA générative, RAG et agents. Vous verrez aussi pourquoi l’IA se trompe, et une méthode concrète pour démarrer un premier cas d’usage en PME avec des garde-fous qualité, sécurité et RGPD.
Deux niveaux de lecture : une version en 2 minutes, puis une version détaillée orientée action en entreprise. Pour compléter, vous pouvez consulter nos ressources IA pour PME.
Comment fonctionne l’IA en 2 minutes
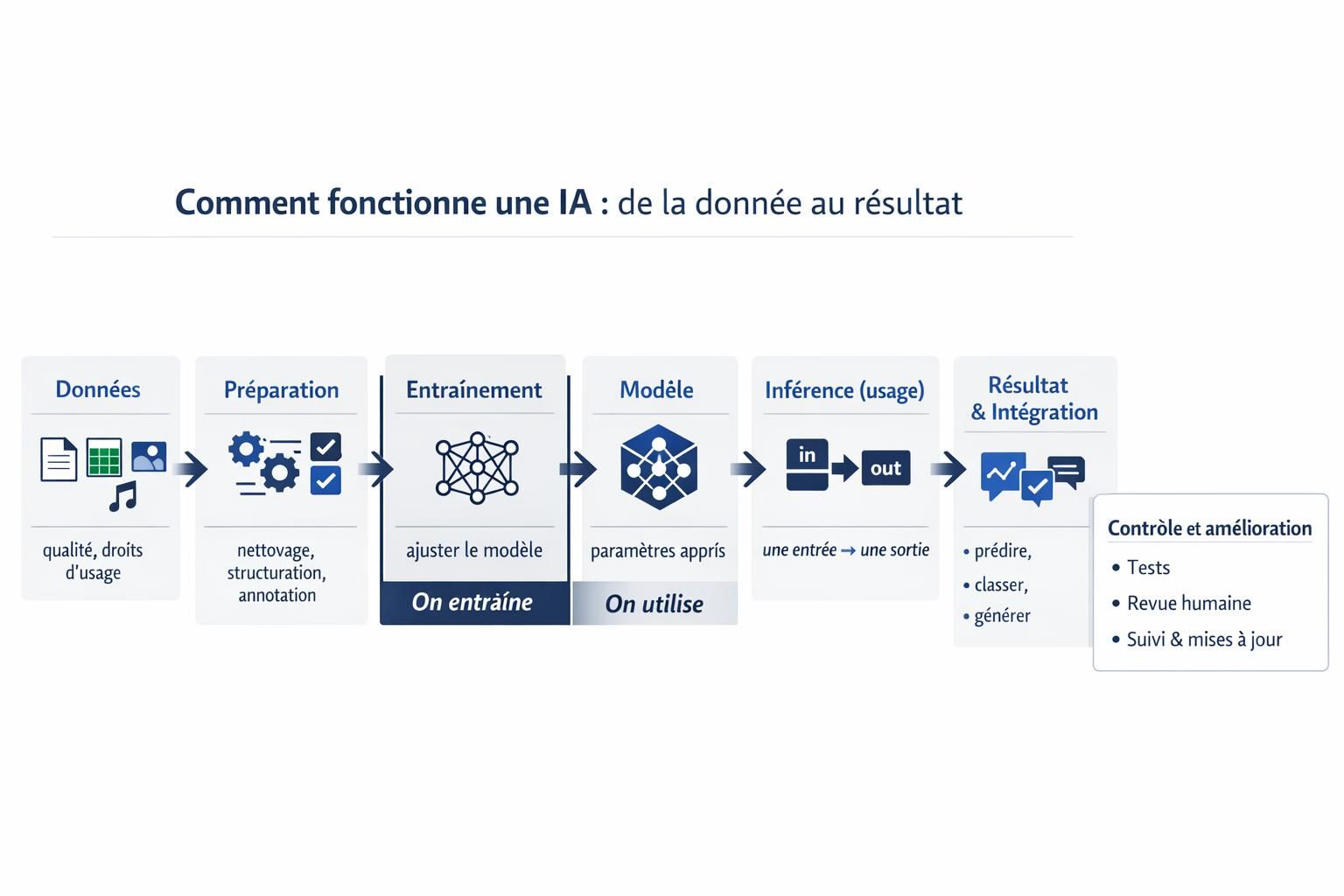
Une IA est un outil statistique très entraîné : on lui donne des entrées, elle applique un modèle appris sur des données, et elle produit une sortie. Ce que l’on appelle intelligence est souvent une capacité à reconnaître des patterns et à générer la réponse la plus plausible selon son entraînement et votre contexte.
- Une IA reçoit des entrées : un texte, une image, un tableau, un son, une requête.
- Elle applique un modèle : une représentation interne apprise qui transforme l’entrée.
- Elle produit une sortie : prédiction, recommandation, classement, résumé, contenu, aide à la décision.
- Le modèle a été amélioré par apprentissage sur des données et un objectif : imiter des exemples, minimiser des erreurs, maximiser une récompense.
- Elle doit être évaluée et encadrée : tests, contrôle qualité, règles d’usage, sécurité et conformité.
Qu’est-ce qu’un système d’IA exactement
Une définition simple et stable
Définition (OCDE) : un système d’IA est un système capable de recevoir des entrées, de faire une inférence à partir d’un modèle, et de produire des sorties telles que des prédictions, des recommandations, des contenus ou des décisions, dans le but d’atteindre des objectifs définis. Source : OCDE.
Cette définition est utile en entreprise car elle met l’accent sur trois points concrets : des objectifs, une étape d’inférence, et des sorties exploitables dans un processus métier.
IA, algorithme, automatisation, data science : ce qui change
Pour éviter les confusions fréquentes en PME, voici des repères simples.
| Terme | À retenir en 1 phrase |
|---|---|
| IA | Un ensemble de techniques qui permettent à un système de produire des sorties utiles à partir d’entrées, souvent en apprenant à partir de données. |
| Algorithme | Une suite d’étapes pour résoudre un problème : une IA utilise des algorithmes, mais tout algorithme n’est pas une IA. |
| Automatisation | Exécuter un processus sans intervention humaine : on peut automatiser sans IA, et on peut utiliser l’IA pour automatiser. |
| Machine learning | Une IA qui apprend des comportements à partir d’exemples de données plutôt que d’être entièrement codée à la main. |
| Deep learning | Une sous-famille du machine learning basée sur des réseaux de neurones profonds, efficace pour vision, texte et audio. |
| Data science | Une discipline plus large qui combine données, statistiques, visualisation et modélisation pour comprendre et piloter une activité. |
De quoi une IA a besoin pour fonctionner
Les données : le carburant, mais pas seulement
Sans données pertinentes, une IA a peu de chances d’être utile. Mais la quantité ne suffit pas : il faut des données adaptées à la tâche, représentatives, et exploitables dans votre contexte métier.
- Texte : emails, tickets support, comptes rendus, procédures, contrats, FAQ interne.
- Tableaux : CRM, ERP, historiques de ventes, stocks, délais, données comptables.
- Images : photos produits, documents scannés, contrôles qualité visuels.
- Audio : appels, réunions, dictées, centre de contact.
En PME, le point bloquant n’est pas toujours l’absence de données, mais leur dispersion, leur qualité, leurs droits d’usage, et la capacité à les relier à un objectif clair.
Les labels et l’annotation quand l’IA doit apprendre avec supervision
Quand vous voulez qu’une IA apprenne à reconnaître quelque chose de précis, vous avez souvent besoin d’exemples annotés, c’est-à-dire des données accompagnées d’une réponse attendue. La CNIL rappelle que l’annotation est un maillon critique : si les annotations sont incohérentes, biaisées ou floues, le modèle apprendra ces défauts. Source : CNIL sur l’annotation des données.
Checklist d’annotation utile en PME
- Définir des catégories non ambiguës et documentées.
- Former les personnes qui annotent, avec des exemples et contre-exemples.
- Vérifier la cohérence entre annotateurs, surtout sur les cas limites.
- Tracer les décisions : pourquoi tel exemple a été classé ainsi.
- Prévoir un jeu de test séparé, jamais utilisé pour entraîner.
Les objectifs et les critères de réussite
Une IA est rarement un projet purement technique. Elle doit servir un objectif métier, et cet objectif doit se traduire en critères observables.
- Qualité : pertinence des réponses, conformité aux procédures, exactitude factuelle.
- Temps : réduction du temps de traitement, accélération de la rédaction, tri plus rapide.
- Fiabilité : stabilité des résultats, capacité à gérer les cas atypiques.
- Satisfaction : retours des utilisateurs internes, retours clients pour le support.
- Risque : diminution des erreurs sensibles, meilleure traçabilité des décisions.
Comment une IA apprend, étape par étape
Entraînement : ajuster un modèle à partir d’exemples
Apprendre signifie ajuster le modèle pour qu’il produise la bonne sortie plus souvent. La définition de l’apprentissage automatique (CNIL) décrit le machine learning comme une approche où un système améliore ses performances sur une tâche en s’appuyant sur des données, plutôt que sur des règles codées exhaustivement.
- Choisir une tâche : classer des emails, détecter une anomalie, générer une réponse, reconnaître un défaut.
- Préparer les données : nettoyer, dédupliquer, structurer, gérer les valeurs manquantes, documenter.
- Choisir un modèle : du modèle simple au réseau de neurones, selon la complexité et les contraintes.
- Mesurer l’erreur : comparer la sortie du modèle à la sortie attendue, selon un critère choisi.
- Ajuster les paramètres : modifier le modèle pour réduire l’erreur sur les données d’entraînement.
- Tester sur des données jamais vues : vérifier que le modèle généralise et ne récite pas.
Les trois grandes familles d’apprentissage à connaître
Les notes d’introduction du MIT sur le machine learning structurent bien trois paradigmes utiles pour comprendre les cas d’usage.
| Famille | Objectif | Exemple simple | Usage PME typique |
|---|---|---|---|
| Supervisé | Apprendre à prédire une sortie connue. | Classer un ticket en catégorie. | Tri d’emails, scoring simple, extraction de champs si vous avez des exemples attendus. |
| Non supervisé | Trouver des structures sans étiquettes. | Regrouper des clients par comportements. | Segmentation, détection de groupes, exploration de données. |
| Renforcement | Apprendre par essais et récompenses. | Optimiser une stratégie dans un environnement. | Plus rare en PME, plutôt optimisation de décisions dans des cas bien cadrés. |
Généralisation, surapprentissage et pourquoi les tests sont indispensables
Un modèle utile doit bien fonctionner sur des cas nouveaux, pas uniquement sur les exemples déjà vus. Les supports de cours de Stanford sur le machine learning insistent sur ce point : un modèle peut surapprendre, c’est-à-dire mémoriser des détails des données d’entraînement au lieu d’apprendre des règles générales. En pratique, cela peut se traduire par des erreurs client, des tâches mal routées ou des décisions incohérentes au fil du temps (donc un risque business).
Signaux d’alerte fréquents en entreprise
- Très bon résultat en test interne, mais résultats instables en production.
- Erreurs concentrées sur un type de client, une région, une gamme de produits.
- Modèle qui se dégrade quand vos processus changent ou quand la saisonnalité arrive.
- Difficulté à expliquer pourquoi le modèle se trompe sur des cas simples.
Que se passe-t-il quand vous utilisez une IA
Inférence : la phase où le modèle produit une réponse
L’entraînement fabrique un modèle. L’inférence est le moment où vous l’utilisez. En inférence, le modèle ne réapprend pas forcément : il applique ce qu’il a déjà appris pour produire une sortie.
Schéma textuel utilisable pour expliquer à un collègue :
- Entrée : votre demande, un document, une image, un formulaire.
- Traitement : le modèle transforme l’entrée selon ses paramètres.
- Sortie : une prédiction, une réponse, un classement, un contenu.
- Contrôle : vérification humaine ou automatique, puis intégration au processus.
Pourquoi la même question peut donner des réponses différentes
Ce phénomène surprend souvent. Il s’explique par plusieurs facteurs.
- Votre entrée change : un détail de contexte, un document joint, une instruction manquante.
- Le modèle change : version différente, réglages, mise à jour de l’outil.
- Le cadre change : contraintes de longueur, de ton, de sources, ou de format.
- Pour l’IA générative : une part de variabilité peut être introduite pour produire des formulations différentes au lieu de répéter toujours la même.
La boucle d’amélioration en entreprise
Dans une PME, vous obtenez de meilleurs résultats en traitant l’IA comme un processus à améliorer, pas comme un outil magique.
- Collecter les retours utilisateurs : où cela aide, où cela gêne, où cela trompe.
- Mesurer la qualité : échantillons, critères simples, cas limites.
- Ajuster : consignes, gabarits, sources, règles de validation, paramètres.
- Mettre à jour : enrichir la base documentaire, réentraîner si pertinent, corriger les données.
- Documenter : ce qui est autorisé, ce qui est interdit, comment vérifier, qui valide.
IA classique et IA générative : quelles différences de fonctionnement
Pour choisir la bonne approche, il faut comparer ce que chaque famille produit, ce qu’elle nécessite, et ses limites. Voici un comparatif opérationnel, réutilisable pour cadrer un cas d’usage.
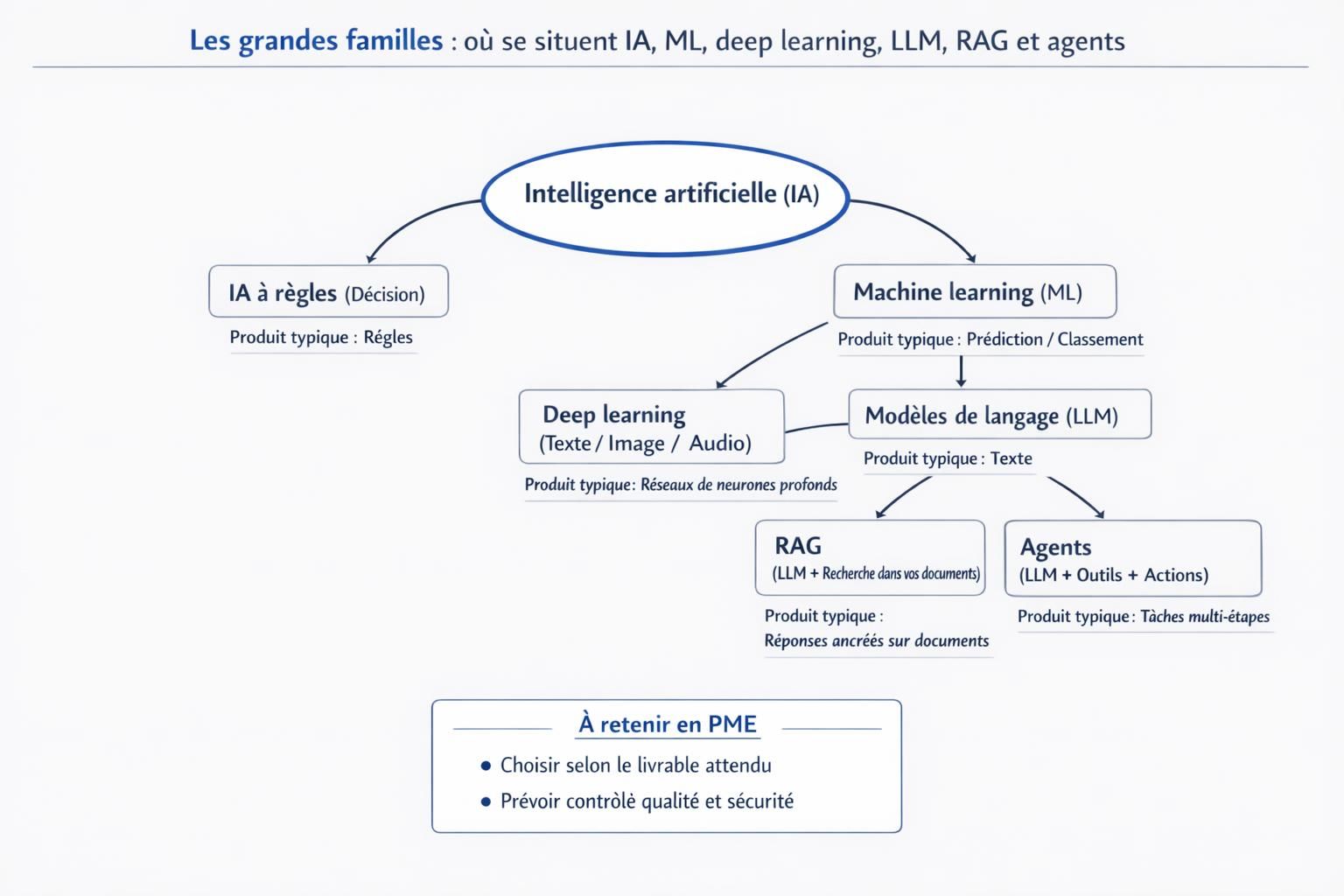
| Type | Ce que ça produit | Données nécessaires | Forces | Limites | Exemples en PME |
|---|---|---|---|---|---|
| IA à règles | Des décisions déterministes. | Règles humaines. | Simple, explicable. | Fragile dès que le cas sort des règles. | Routage de demandes, contrôles de cohérence. |
| Machine learning | Des prédictions ou des classements. | Historiques, parfois annotés. | Efficace sur tâches répétitives. | Dépendant des données, risque de surapprentissage. | Tri de tickets, prévision, détection d’anomalies. |
| Deep learning | Des prédictions avancées sur texte, image, audio. | Souvent volumineuses et variées. | Très performant sur perception et langage. | Besoin de calcul, explicabilité parfois plus difficile. | OCR amélioré, classification d’images, transcription. |
| LLM | Du texte et du raisonnement apparent à partir de contexte. | Grandes quantités de texte pour l’entraînement initial, puis instructions et contexte en usage. | Polyvalent, très bon pour reformuler, synthétiser, structurer. | Peut inventer, peut ignorer vos règles si elles sont floues. | Rédaction encadrée, aide à la réponse, analyse de documents. |
| RAG | Des réponses ancrées sur vos documents. | Base documentaire propre et à jour. | Réduit les réponses hors-sol, améliore la pertinence métier. | Dépend de la qualité des documents, ne supprime pas totalement les erreurs. | Assistant support sur base de connaissances, aide interne procédures. |
| Agents | Des actions orchestrées sur plusieurs outils. | Accès aux outils et règles. | Exécute des tâches multi-étapes. | Risque d’actions non souhaitées si mal cadré, besoin de garde-fous forts. | Préparation de dossiers, collecte d’infos, pré-remplissage avec validation. |
Comment fonctionne l’IA générative de type ChatGPT
Si vous cherchez des exemples concrets d’usages, de consignes et de garde-fous, vous pouvez consulter notre guide complet sur l’utilisation de ChatGPT en entreprise. Ici, on se concentre sur la mécanique de base pour mieux cadrer vos tests.
Les tokens et la prédiction du mot suivant
Un modèle de langage découpe le texte en unités appelées tokens, puis prédit la suite la plus probable selon le contexte. Il ne “cherche” pas automatiquement une vérité vérifiée : il calcule une continuité linguistique cohérente avec ce qu’il a appris et ce que vous lui fournissez. En entreprise, on vise donc des réponses utiles et vérifiables, d’où l’intérêt des sources, du RAG et des contrôles.
Mini-exemple illustratif :
- Contexte : Rédigez un email de relance poli.
- Le modèle choisit une suite de tokens plausibles : Bonjour, je me permets de vous recontacter…
- Puis il continue jusqu’à produire un message complet selon vos contraintes.
Pourquoi un LLM peut sembler intelligent
Un LLM peut donner l’impression de comprendre, parce qu’il maîtrise très bien les formes du langage. Mais il faut distinguer perception et réalité technique.
- Raison perçue : il répond vite et avec assurance. Réalité : il choisit des formulations très probables, ce qui ressemble à de la confiance.
- Raison perçue : il synthétise bien. Réalité : il combine et reformule des patterns vus dans des textes, parfois sans vérifier les faits.
- Raison perçue : il suit des consignes. Réalité : il suit des signaux de votre prompt et du contexte, mais peut dévier si c’est ambigu.
- Raison perçue : il raisonne. Réalité : il enchaîne des étapes de texte cohérentes, ce qui peut imiter un raisonnement, sans garantie de justesse.
Le rôle des instructions et du contexte
En entreprise, la qualité des résultats dépend beaucoup de ce que vous fournissez comme contexte. Une bonne consigne réduit l’ambiguïté et facilite le contrôle.
- Objectif : à quoi doit servir la réponse, et dans quel processus.
- Audience : client, prospect, interne, direction, nouveau collaborateur.
- Format : email, plan, tableau logique, procédure, synthèse en points.
- Contraintes : ton, longueur, vocabulaire, interdits, conformité.
- Sources : documents à utiliser, règles internes, éléments factuels fournis.
- Critères de validation : ce qui rend la sortie acceptable ou non.
RAG : faire répondre l’IA avec vos documents
Le RAG, pour Retrieval Augmented Generation, combine un modèle génératif et un mécanisme de recherche dans vos contenus. L’idée est simple : avant de générer, le système va chercher des passages pertinents dans votre base documentaire, puis les injecte dans le contexte de réponse.
- Vous posez une question : par exemple sur une procédure, un produit ou une règle.
- Le système recherche dans vos documents les passages les plus proches du besoin.
- Il fournit ces extraits au modèle de langage comme contexte.
- Le modèle génère une réponse en s’appuyant sur ce contexte.
- Vous contrôlez et améliorez : documents, règles, et tests sur des cas réels.
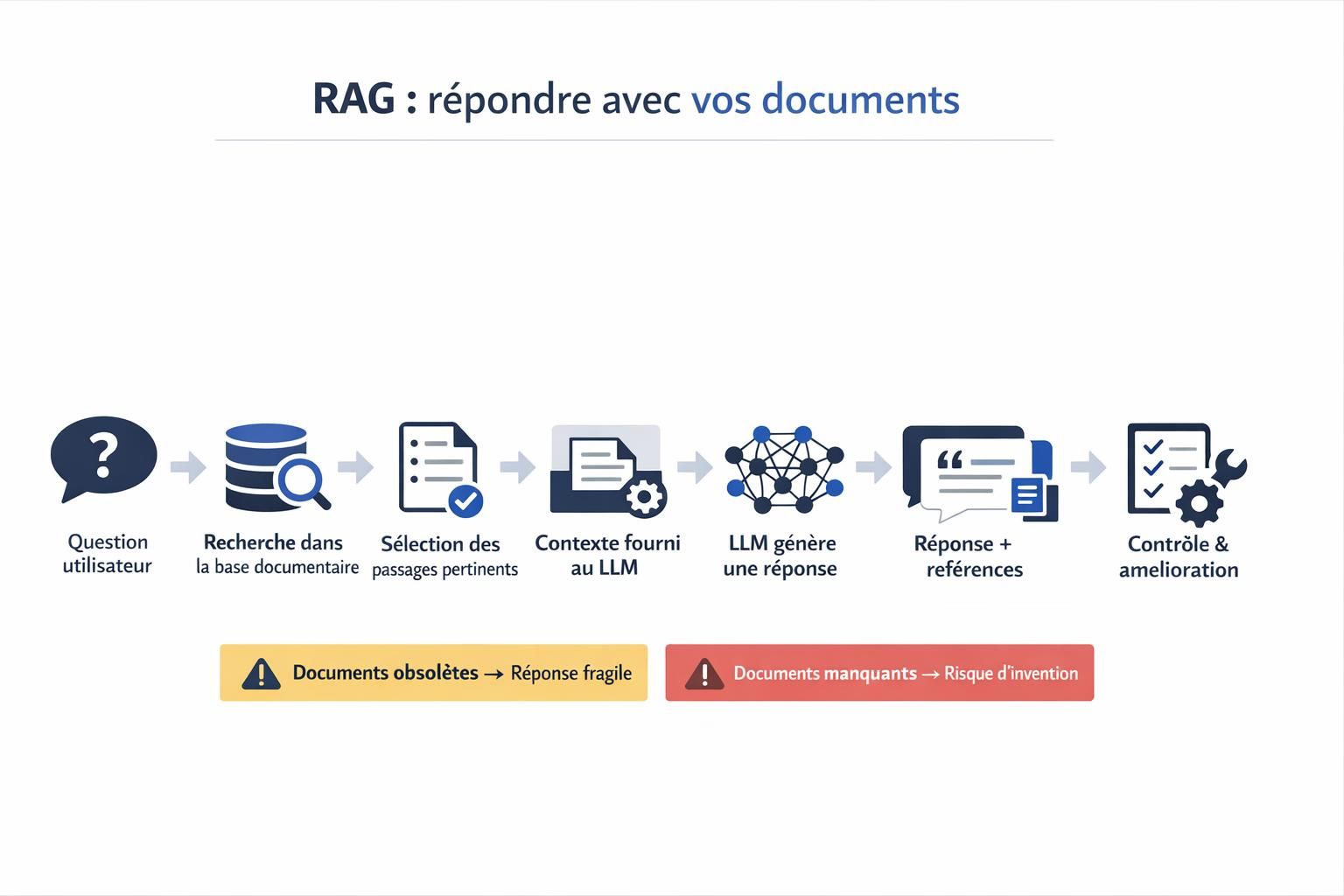
Promesse réaliste : le RAG réduit le risque d’hallucination en ancrant la réponse sur vos documents, mais ne le supprime pas totalement. Si la base est incomplète, obsolète ou contradictoire, la réponse peut rester fragile.
Cas d’usage PME typiques : assistant support client sur base de connaissances, FAQ interne, aide à la rédaction de devis selon des catalogues et conditions, assistant procédures qualité.
Pourquoi l’IA se trompe et comment réduire les erreurs
Hallucinations, biais, dérive, données incomplètes
Comprendre les erreurs vous aide à mettre les bons garde-fous. Voici une grille simple, utilisable en atelier d’équipe.
| Problème | Cause fréquente | Parade simple |
|---|---|---|
| Hallucination | Manque de sources fournies, questions trop ouvertes, besoin de précision factuelle. | Imposer des sources internes, demander d’indiquer les incertitudes, refuser les affirmations non vérifiables. |
| Biais | Données d’entraînement non représentatives, historiques qui reflètent des décisions passées. | Tester sur des cas variés, vérifier l’équité sur populations concernées, corriger les données et les règles. |
| Dérive | Évolution du métier, des produits, des demandes clients. | Surveiller la qualité dans le temps, mettre à jour documents et modèles, formaliser un cycle de maintenance. |
| Données incomplètes | Documents manquants, procédures non écrites, CRM mal rempli. | Traiter la documentation et la qualité des données comme un chantier prioritaire. |
| Surconfiance | Sortie fluide et persuasive. | Exiger une validation sur les points sensibles, introduire des contrôles automatiques et humains. |
Un protocole de contrôle qualité simple pour une PME
Vous pouvez réduire fortement les erreurs avec une routine avant, pendant et après usage.
- Avant : cadrer le périmètre et les règles. Définir ce qui est autorisé, interdit, et les cas qui exigent validation.
- Avant : définir les sources de vérité. Décider quels documents font foi et qui en est responsable.
- Pendant : utiliser des consignes structurées. Demander un format de sortie constant, et préciser quand le modèle doit dire « je ne sais pas ».
- Pendant : tester sur un lot de cas réels. Inclure des cas simples, des cas limites, et des cas sensibles.
- Après : organiser une revue humaine. Valider avant envoi client, avant décision, ou avant publication.
- Après : journaliser. Garder une trace des prompts, des versions, et des corrections pour apprendre.
Ce que la revue humaine doit vérifier
- Faits : noms, dates, conditions, références produit, éléments juridiques.
- Conformité : respect des règles internes, du RGPD, des engagements contractuels.
- Ton : alignement avec la marque, absence de formulations risquées ou ambiguës.
- Risque métier : promesses non tenables, conseils inadaptés, décisions non justifiées.
- Données sensibles : absence d’informations confidentielles ou personnelles non nécessaires.
Comment appliquer ces principes dans une PME
Méthode en 7 étapes pour passer de la théorie à un premier cas d’usage
Cette méthode vise un premier résultat concret et maîtrisé, sans transformer votre PME en laboratoire.
- Choisir un irritant métier prioritaire : tâche répétitive, goulot d’étranglement, qualité variable, forte charge de rédaction.
- Définir l’objectif et le livrable attendu : une réponse type, un compte rendu, un tri, une synthèse, une aide à la décision.
- Recenser données et documents disponibles : où sont-ils, qui les maintient, quelle qualité, quelles contraintes de confidentialité.
- Choisir l’approche IA adaptée : automatisation IA & no-code, machine learning, IA générative, RAG, ou combinaison.
- Prototyper en environnement contrôlé : petit périmètre, utilisateurs pilotes, règles claires, validation systématique au début.
- Évaluer avec des critères simples : qualité, temps, fiabilité, risques, adoption, effort d’intégration.
- Déployer avec règles, formation ChatGPT & IA générative, suivi : charte d’usage, processus de validation, support interne, plan d’amélioration continue.
Grille Go No Go avant déploiement
Avant de généraliser, vérifiez ces points. Si plusieurs sont rouges, restez en pilote.
- Qualité : la sortie est-elle suffisamment fiable pour le contexte, et sur quels cas échoue-t-elle.
- Sécurité : qui a accès, où vont les données, comment limiter la fuite d’informations.
- RGPD : y a-t-il des données personnelles, et avez-vous une base légale, une finalité, une information adaptée.
- Dépendance fournisseur : que se passe-t-il si l’outil change, augmente ses prix, ou modifie ses conditions.
- Effort d’intégration : est-ce utilisable dans le flux de travail réel, pas seulement en démonstration.
- Adoption : les équipes comprennent-elles quand l’utiliser, comment vérifier, et quand s’abstenir.
Gouvernance minimale qui évite la plupart des problèmes
Vous n’avez pas besoin d’une organisation lourde pour bien faire. Une gouvernance légère, claire et appliquée suffit souvent.
- Un référent IA : pilote le cadrage, les règles, les priorités et la documentation.
- Un validateur métier : arbitre la qualité, la conformité aux procédures et les cas limites.
- Une charte d’usage : ce qui est autorisé, interdit, et les exigences de validation.
- Gestion des accès : comptes nominaux, droits limités, séparation entre test et production.
- Gestion des incidents : quoi faire en cas d’erreur critique, de fuite, ou de réponse inappropriée.
- Suivi : revues régulières, amélioration des documents et des prompts, surveillance des dérives.
Pour structurer votre approche risque, le cadre NIST AI RMF 1.0 est souvent cité comme référence : il met l’accent sur la gouvernance, la cartographie des risques, la mesure et la gestion dans le temps, plutôt qu’un contrôle ponctuel.
Exemples concrets par fonction en PME
Ces exemples sont volontairement pragmatiques. Pour chacun, on précise le problème, une solution IA réaliste, les données nécessaires, des critères de suivi et des garde-fous.
- Commercial
- Problème : produire des comptes rendus et relances cohérents après rendez-vous.
- Solution IA : brouillon de compte rendu et email de relance à partir de notes structurées, avec validation humaine.
- Données nécessaires : trame de compte rendu, offres, éléments de langage, notes de rendez-vous.
- KPI de suivi : qualité perçue, temps de production, taux de correction, taux de réponse.
- Risques et garde-fous : promesses commerciales excessives, erreurs produit. Garde-fou validation systématique avant envoi.
- Commercial appels d’offres
- Problème : analyser un cahier des charges et préparer une première grille de réponse.
- Solution IA : extraction des exigences, questions à clarifier, plan de réponse, aide à la rédaction sur base de vos contenus.
- Données nécessaires : offres, références, bibliothèques de réponses, modèles de documents.
- KPI de suivi : complétude, cohérence, temps de préparation, retours avant soumission.
- Risques et garde-fous : erreurs de conformité, clauses mal interprétées. Garde-fou relecture experte et checklists.
- Support client
- Problème : répondre vite tout en respectant des procédures.
- Solution IA : assistant support avec RAG sur base de connaissances, proposant des réponses et étapes de diagnostic.
- Données nécessaires : FAQ, procédures, historiques de tickets, politiques SAV.
- KPI de suivi : taux de résolution, satisfaction, escalades, cohérence des réponses.
- Risques et garde-fous : réponse inexacte, divulgation d’informations. Garde-fou sources internes et validation sur cas sensibles.
- Marketing et communication
- Problème : décliner des contenus pour plusieurs canaux sans perdre la cohérence.
- Solution IA : génération de variantes de posts, titres, plans, scripts, puis validation éditoriale.
- Données nécessaires : charte éditoriale, persona, offres, éléments de preuve disponibles.
- KPI de suivi : cohérence de marque, taux de correction, performance par canal.
- Risques et garde-fous : affirmations non sourcées, ton inadéquat. Garde-fou consignes et revue systématique.
- RH
- Problème : répondre aux questions récurrentes et homogénéiser les fiches de poste.
- Solution IA : FAQ interne encadrée et aide à la rédaction à partir de référentiels, avec validation RH.
- Données nécessaires : politiques internes, accords, modèles de fiches, procédures onboarding.
- KPI de suivi : satisfaction interne, cohérence, réduction des allers-retours.
- Risques et garde-fous : données personnelles, interprétation juridique. Garde-fou minimisation des données et validation.
- Finance et administratif
- Problème : extraire des informations de factures et contrôler la cohérence des pièces.
- Solution IA : extraction de champs et contrôles simples, puis validation comptable.
- Données nécessaires : factures, règles de contrôle, référentiels fournisseurs.
- KPI de suivi : taux d’erreurs, temps de traitement, taux de rejets.
- Risques et garde-fous : erreurs de saisie, non-conformité. Garde-fou validation humaine et règles automatiques.
- Opérations et qualité
- Problème : procédures peu homogènes, connaissances dispersées, reporting chronophage.
- Solution IA : assistant procédural interne avec RAG, et génération de synthèses de reporting à partir de données fournies.
- Données nécessaires : procédures, modes opératoires, modèles de rapports, glossaire interne.
- KPI de suivi : cohérence des pratiques, temps de recherche, qualité des rapports.
- Risques et garde-fous : utilisation d’une version obsolète. Garde-fou gouvernance documentaire et mises à jour.
Sécurité, confidentialité et RGPD : les points à comprendre
Données personnelles et cycle de vie d’un système d’IA
Dès qu’un système d’IA traite des données personnelles, le RGPD peut s’appliquer. La CNIL insiste sur l’importance de raisonner en cycle de vie : collecte des données, préparation, apprentissage éventuel, puis usage opérationnel et amélioration. Les risques et obligations ne sont pas les mêmes à chaque étape. Repères CNIL sur IA et conformité RGPD.
- Collecte : avez-vous une finalité claire, une base légale, et des données pertinentes au regard de l’objectif.
- Apprentissage : minimisation, qualité, gestion des biais, documentation des choix.
- Usage : information des personnes si nécessaire, contrôle des accès, traçabilité, supervision humaine.
- Amélioration : gestion de la dérive, mise à jour des données, conservation limitée, suivi des incidents.
Mesures simples pour limiter les risques
Sans entrer dans des dispositifs lourds, vous pouvez sécuriser fortement un premier déploiement avec des mesures simples.
- Minimisation : ne fournir que les données nécessaires à la tâche, éviter le surplus.
- Anonymisation ou pseudonymisation quand c’est possible, surtout en phase de test.
- Choix d’outils et de paramètres : définir où les données sont traitées et conservées, et qui y accède.
- Gestion des accès : comptes nominaux, droits limités, séparation test et production.
- Journalisation : conserver une trace des usages sur les cas sensibles, pour audit et amélioration.
- Clauses et règles internes : clarifier confidentialité, usages autorisés, et escalades en cas d’incident.
- Formation : apprendre aux équipes à éviter l’injection de données sensibles, et à valider les outputs.
Conclusion
Comprendre comment fonctionne l’IA revient à suivre un fil logique : données, entraînement, modèle, inférence, puis contrôle et amélioration. L’IA classique vise surtout la prédiction et le classement, tandis que l’IA générative produit du contenu et peut être renforcée par le RAG pour mieux s’appuyer sur vos documents.
Ses limites sont connues : erreurs, biais, hallucinations, dérive. La bonne réponse n’est pas d’arrêter, mais d’encadrer : objectifs clairs, données propres, tests, revue humaine et gouvernance légère.
Si vous souhaitez passer de la compréhension à un premier cas d’usage déployé, SchoolIA propose un accompagnement IA pour PME avec une approche pragmatique : cadrage, montée en compétence des équipes, mise en place de règles d’usage, prototype, évaluation et déploiement opérationnel.
FAQ
Quelle est la différence entre IA, machine learning et deep learning
L’IA est un terme large pour désigner des systèmes qui produisent des sorties utiles à partir d’entrées. Le machine learning est une sous-partie de l’IA où le système apprend à partir de données, comme l’explique la CNIL. Le deep learning est une sous-partie du machine learning, basée sur des réseaux de neurones profonds.
Quelle est la différence entre entraînement et inférence
L’entraînement est la phase où l’on ajuste un modèle à partir d’exemples pour qu’il fasse moins d’erreurs. L’inférence est la phase d’utilisation : vous donnez une entrée et le modèle produit une sortie. En entreprise, on encadre l’inférence par des tests et des contrôles qualité, car une erreur peut avoir un impact client.
Pourquoi une IA générative hallucine et comment limiter ce risque
Une IA générative peut halluciner car elle produit un texte plausible, pas des faits vérifiés. Si le contexte est insuffisant ou si la question exige une précision factuelle, elle peut inventer. Pour limiter le risque, fournissez des sources, imposez un format, utilisez un RAG avec documents internes et gardez une validation humaine sur les points sensibles.
Est-ce que l’IA peut apprendre à partir des données de mon entreprise sans les divulguer
C’est possible, mais cela dépend de l’outil, du paramétrage et du mode de déploiement. Vérifiez où les données sont traitées, si elles sont conservées, si elles servent à entraîner le modèle, et qui y accède. En présence de données personnelles, appliquez minimisation, contrôle des accès et repères CNIL/RGPD.
Quels sont les premiers cas d’usage IA les plus simples à déployer en PME
Les plus simples sont souvent ceux à faible risque et à forte répétitivité : brouillons d’emails et comptes rendus avec validation, synthèse de documents, recherche dans une base interne via RAG, génération de gabarits, tri de demandes, extraction de champs sur documents. Démarrez par un pilote, des critères clairs et une revue humaine.